Claude Code 自动记忆系统详解:从入门到进阶
快速结论
Claude Code 的 Auto Memory 功能标志着 AI 编程从「被动响应」向「主动学习」的转变。通过层次化的记忆体系,它能有效减少重复指令输入,大幅提升开发效率。但用户需要精细管理记忆内容,以避免上下文窗口溢出。
核心评估维度
| 维度 | 表现 | 说明 |
|---|---|---|
| 记忆层级 | 6 层结构 | 从系统级到 Auto Memory,优先级逐级递增 |
| Auto Memory 加载限制 | 前 200 行 | 仅加载 MEMORY.md 头部,需保持精简索引 |
| 加载模式 | 3 种 | 启动全量、按需读取、条件加载 |
| 优先级逻辑 | Git 风格 | 越具体(Local)优先级越高 |
六层记忆架构
Claude Code 的记忆系统采用类似 Git 的层级设计,从底层到顶层分别是:
- 系统级规则 — 强制安全扫描等不可覆盖的基础策略
- 全局 CLAUDE.md — 跨项目通用的个人偏好
- 项目 CLAUDE.md — 项目根目录的团队共享配置
- Local CLAUDE.md — 个人私有配置,不提交到 Git
- 目录级 CLAUDE.md — 子目录的局部规则覆盖
- Auto Memory — AI 主动学习并记录的开发模式
优先级遵循「越具体越优先」的原则,Local 配置会覆盖全局配置。

初始化配置:slash init
对于新项目,推荐通过 /init 命令快速生成 CLAUDE.md 模板。它会扫描项目结构并自动填充基础规则,包括语言偏好、测试命令、代码风格等。
生成后建议手动检查并补充以下内容:
- 项目特有的构建/部署命令
- 团队约定的代码风格规范
- 常用的调试技巧和已知坑点
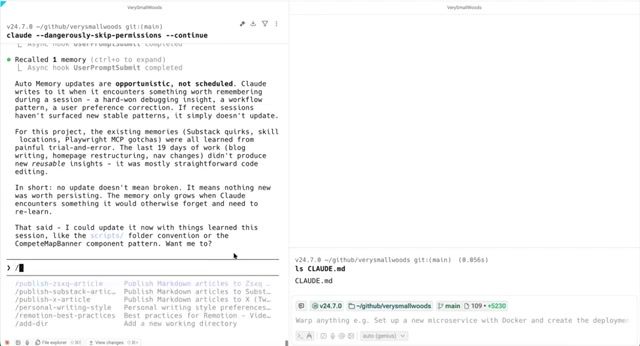
Auto Memory 的工作机制
Auto Memory 并非简单的「全部记住」。它是按需触发的 — 当 Claude 在会话中遇到值得记录的模式(调试经验、工作流偏好、用户纠正等),才会主动写入记忆文件。
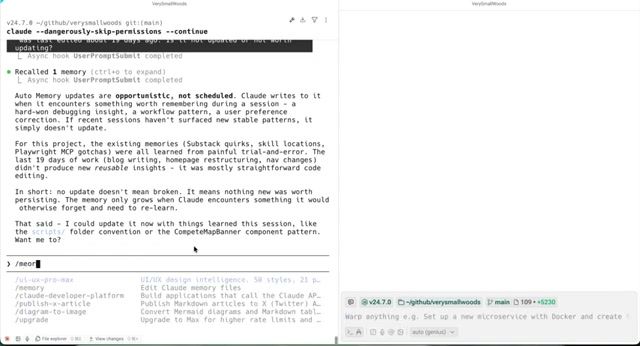
关键限制:MEMORY.md 仅加载前 200 行。超出部分需要拆分为独立文件(如 debugging.md、patterns.md),并在主文件中通过链接索引。
三种加载模式
理解加载模式是避免「配置不生效」问题的关键:
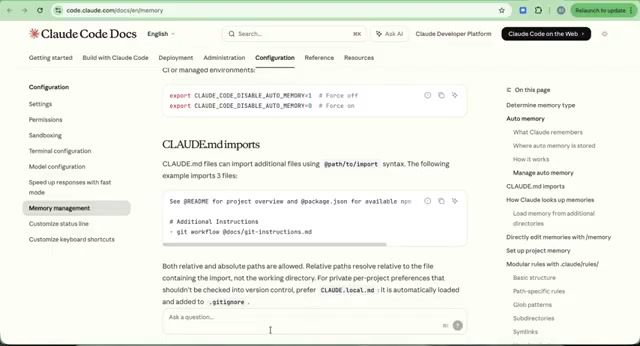
- 启动全量加载 —
CLAUDE.md和MEMORY.md前 200 行在每次会话开始时自动加载 - 按需读取 — 拆分出的子文件(如
debugging.md)仅在 AI 判断相关时才读取 - 条件加载 — 目录级
CLAUDE.md仅在操作对应目录下的文件时生效
需要注意的问题
上下文窗口限制。 MEMORY.md 超过 200 行的部分不会被自动加载。必须通过拆分文件来管理详细信息,主文件仅保留精简索引。
信息冗余风险。 记忆并非越多越好。过多无关信息会挤占上下文窗口,反而导致 AI 性能下降。定期清理过时或低价值的记忆条目很重要。
维护成本。 初始生成的 CLAUDE.md 可能不够完美,需要在使用中持续微调。建议每隔一段时间审查记忆内容,删除错误或过时的指令。
适合谁用
- 追求极致开发效率、频繁使用 AI 辅助编程的开发者
- 需要在多项目间保持统一代码风格和测试规范的工程师
- 习惯使用 Git 进行配置管理、偏好声明式配置的团队
如果只是偶尔写写脚本,或不需要长期维护项目,Auto Memory 带来的收益有限。
总结
Claude Code 的六层记忆架构设计合理,Auto Memory 的主动学习能力是真正的效率倍增器。核心建议:保持 MEMORY.md 精简,善用文件拆分,定期清理过时记忆。掌握这些,AI 协作效率会有质的提升。
如果你在考察更多 AI 编程工具,推荐阅读 Codex AI 编程工具测评。想用 RSS 高效追踪 AI 领域动态,可以参考 Follow RSS 阅读器使用指南。
